
Digitize your notes with Azure Computer Vision and Python
In this article, you will build a simple Python app that turns your handwritten notes into digital documents using Azure Computer Vision.

In March 2023, Microsoft announced the public preview of Azure Computer Vision Image Analysis 4.0 SDK, which features enhanced capabilities for image captioning, image tagging, object detection, smart crops, people detection, and OCR (Optical Character Recognition). The updated version of Azure Computer Vision is powered by the Florence Foundation model, allowing developers to gain insightful information from their data through visual and natural language interactions. To learn more about the new features available with the Florence Foundation model, please read the post Announcing a renaissance in computer vision AI with Microsoft’s Florence foundation model.
Given this announcement, I decided to update my old article about extracting printed and handwritten text from images to reflect the newly available Read OCR API. In this post, you will learn how to:
Before you begin building your app, take the following steps:
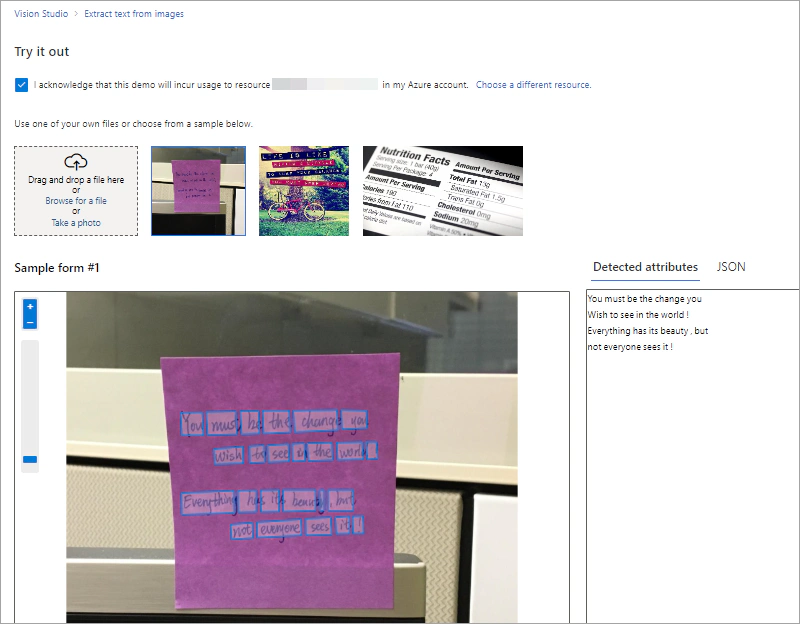
Navigate to the Vision Studio website and sign in using your Vision resource.
In the Featured tab, you can find some commonly used preconfigured features, such as image captioning, tagging, object detection, background removal, and image retrieval.
Navigate to the Optical Character Recognition tab and select the tile Extract text from images, which extracts printed and handwritten text from images, PDFs, and TIFF files in one of the supported languages.
Under Try it out, you can specify the resource that you want to use for the analysis.
Then, select one of the sample images or upload an image for analysis.
On the right pane, you can see the text extracted from the image and the JSON output.
Using the Image Analysis client SDK for Python, we are going to develop a basic application that extracts text from image documents.
First, install the Azure AI Vision client SDK using the following command:
| |
Create a .env file and set two variables in it: CV_KEY and CV_ENDPOINT. These variables should contain the key and endpoint of your Cognitive Services resource, respectively.
Create a new python file and open it in Visual Studio Code or your preferred editor.
Import the following libraries.
| |
Create variables for your Computer Vision resource and authenticate against the service.
| |
Then, select an image to analyze.
| |
VisionSource constructor instead of the local image path: vision_source = cvsdk.VisionSource(url="<URL>").The Image Analysis API provides several computer vision operations, such as generating captions for an image, tags for visual features, and thumbnails, detecting objects or people or reading text from images. For text extraction, include TEXT in the ImageAnalysisOptions features.
| |
Use the following code to get the results from the Computer Vision service.
| |
You can also extend this basic application to display the confidence score for each extracted word and a bounding box around every detected line. The following code uses the Python Imaging Library (Pillow) to open the local image and display a polygon around the detected lines.
| |
In this post, I showed you how to use the latest features of the Azure Computer Vision Image Analysis Read OCR API to extract text from images. You can find more information about what you can do with the service on the Computer Vision Documentation on Microsoft Docs.

Written By
I am a Back-End Engineer at NET2GRID in Greece, with an integrated Master's degree in Electrical and Computer Engineering from the Aristotle University of Thessaloniki. I am interested in AI, IoT, Wireless Communications, and Cloud Technologies, as well as in applications of technology in healthcare and education. I am also a Microsoft AI MVP.
In this article, you will build a simple Python app that turns your handwritten notes into digital documents using Azure Computer Vision.

In this article, you will use the Azure Computer Vision READ API to convert your handwritten notes into digital documents.

In this blog post, you will build a website using Flask and Azure Cognitive Services to extract and translate text from notes.

In this post, you will explore the latest features of Azure Computer Vision and create a basic image analysis app.