
Use HNSW index on Azure Cosmos DB for PostgreSQL for similarity search
Explore vector similarity search using the Hierarchical Navigable Small World (HNSW) index of pgvector on Azure Cosmos DB for PostgreSQL.

Recently, vector embeddings and vector databases have become increasingly popular, enabling the development of new intelligent applications such as vector similarity search. Since I had no prior experience with these concepts, I decided to explore them and document my journey for you.
In this article, you will explore the Image Retrieval functionality of Azure Computer Vision 4.0, which is powered by the Florence Foundation model. You will:
Before starting to build your image vector similarity system, follow these steps:
Sign up for either an Azure free account or an Azure for Students account. If you already have an active subscription, you can use it.
Create a Cognitive Services resource in the Azure portal.
Install Python 3.x, Visual Studio Code, Jupyter Notebook and Jupyter Extension for Visual Studio Code.
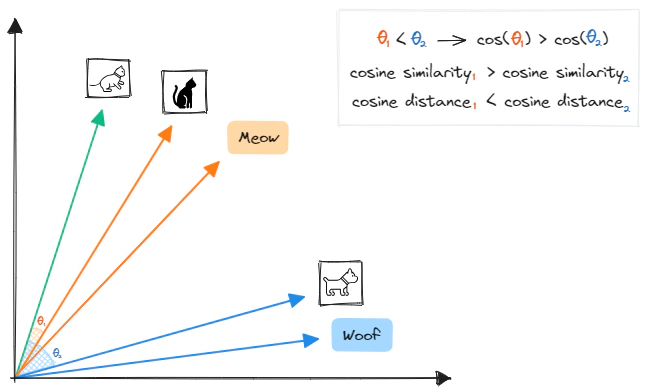
Let’s start by understanding vector embeddings. In simple terms, vector embeddings are numerical representations of data, such as images, text, videos, and audio. These vectors are high-dimensional dense vectors, with each dimension containing information about the original content. By translating data into dense vectors, we can use them to perform tasks like clustering, recommendation, or image search. Additionally, these dense representations allow computers to understand the semantic similarity between two objects. That is, if we represent objects like images, videos, documents, or audio as vector embeddings, we can quantify their semantic similarity by their proximity in a vector space. For example, the embedding vector of an image of a cat will be more similar to the embedding vector of another cat or the word “meow” than that of a picture of a dog or the word “woof”.
There are lots of ways to generate vector embeddings of data. To vectorize your data in Azure, you can use the Azure OpenAI Embeddings models for text documents or the Azure Cognitive Services for Vision Image Retrieval APIs for images and text. The latter is a multi-modal embedding model that enables you to vectorize image and text data and build image search systems.
If you’re interested in learning more about vector embeddings and how they’re created, check out the post “Vector Similarity Search: From Basic to Production” on the MLOps community website!
Vector embeddings capture the semantic similarity of objects, allowing for the development of semantic similarity search systems. Vector similarity search works by searching for images based on the content of the image itself, instead of relying only on manually assigned keywords, tags, or other metadata, as keyword-based search systems do. This approach is usually more efficient and accurate than traditional search techniques, which depend heavily on the user’s capability to find the best search terms.
In a vector search system, the vector embedding of a user’s query is compared to a set of pre-stored vector embeddings to find a list of vectors that are the most similar to the query vector. Since embeddings that are numerically close are also semantically similar, we can measure the semantic similarity by using a distance metric, such as cosine or Euclidean distance.
In this post, we will be utilizing the cosine similarity metric to measure the similarity between two vectors. This metric is equal to the cosine of the angle between the two vectors, or, equivalently, the dot product of the vectors divided by the product of their magnitudes. The cosine similarity ranges from -1 to 1, with a value close to 1 indicating that the vectors are very similar. To help illustrate this, here is a Python function that calculates the cosine similarity between two vectors.
| |
Azure Computer Vision 4.0’s Image Retrieval APIs, powered by the Florence Foundation model, allow for the vectorization of images and text queries. This vectorization converts images and text into coordinates in a 1024-dimensional vector space, enabling users to search a collection of images using text and/or images without the need for metadata, such as image tags, labels, or captions.
Azure Computer Vision provides two Image Retrieval APIs for vectorizing image and text queries: the Vectorize Image API and the Vectorize Text API. The diagram below shows a typical image retrieval process using these APIs.

Navigate to my GitHub repository and download the source code of this article. Open the image-embedding.ipynb Jupyter Notebook in Visual Studio Code and explore the code.
Using the Vectorize Image API, this code generates vector embeddings for 200 images and exports them into a JSON file. After that, two image vector similarity search processes are highlighted: image-to-image search and text-to-image search.
In the image-to-image search process, the reference image is converted into a vector embedding using the Vectorize Image API and the cosine distance is used to measure the similarity between the query vector and the vector embeddings of our image collection. The top matched images are retrieved and displayed alongside the reference image.
In the text-to-image search process, the text query is converted into a vector embedding using the Vectorize Text API and the most similar images are retrieved and displayed based on the cosine similarity between the query vector and their vectors.
Vector databases are a specialized type of database that are designed for handling data as high-dimensional vectors, or embeddings. Vector databases are distinct from traditional databases in that they are optimized to store and query vectors with a large number of dimensions, which can range from tens to thousands, depending on the complexity of the data and the transformation function applied. The diagram below illustrates the workflow of a basic vector search system.
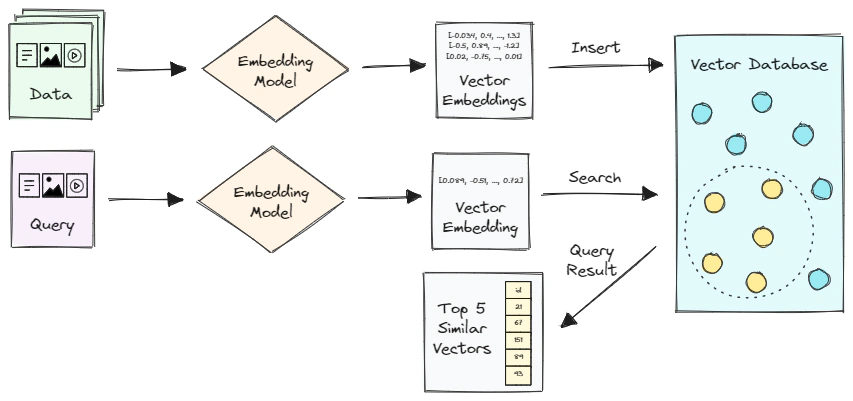
Let’s analyze this further.
As of July 3, 2023, the following Azure services are available for storing and querying vector data.
For this post, I wanted to try out Azure Cosmos DB for PostgreSQL in which vector similarity search is enabled by the pgvector extension. In the sections below, I will show you how to enable the extension, create a table to store vector data, and query the vectors.
Let’s get started!
Sign in to the Azure portal and select + Create a resource.
Search for Azure Cosmos DB. On the Azure Cosmos DB screen, select Create.
On the Which API best suits your workload? screen, select Create on the Azure Cosmos DB for PostgreSQL tile.
On the Create an Azure Cosmos DB for PostgreSQL cluster form fill out the following values:
citus.citus. Select a password that will be used for citus role to connect to the database.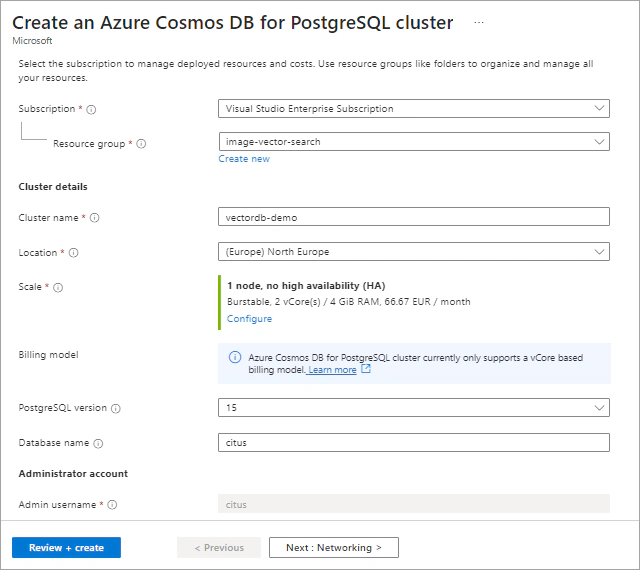
On the Networking tab, select Allow public access from Azure services and resources within Azure to this cluster and create your preferred firewall rule.
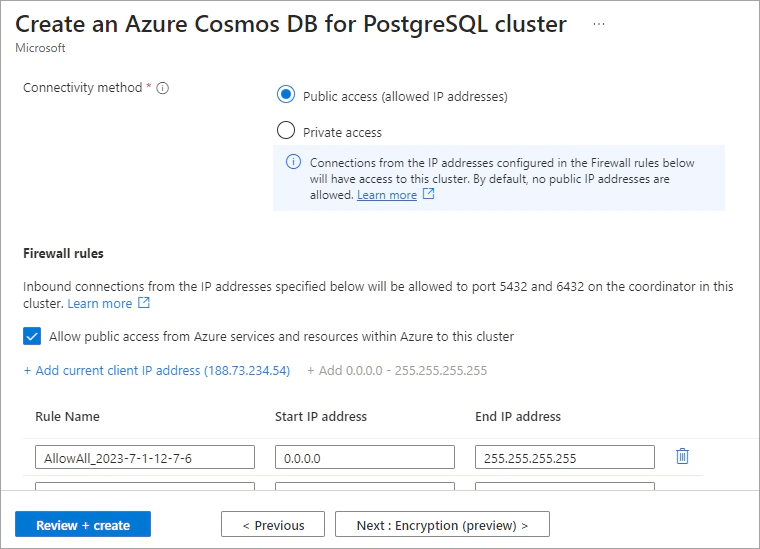
Navigate to the Review + Create tab and then select Create to create the cluster.
Once the deployment is complete, select Go to resource.
Save the Coordinator name, Database name, and Admin username found on the Overview tab of your cluster, as you will need them in a subsequent step.
The pgvector extension adds vector similarity search capabilities to your PostgreSQL database. To use the extension, you have to first create it in your database. To enable the extension, we will use the PSQL Shell.
Select the Quick Start tab on the left pane of your Azure resource and then select the PostgreSQL Shell tile.
Enter your password to connect to your database.
The pgvector extension can be enabled using the following command:
| |
On the PSQL Shell, run the following command to create a table to store vector data.
| |
The table has two columns: one for the image file paths of type TEXT and one for the corresponding vector embeddings of type VECTOR(1024).
Create a new .ipynb file and open it in Visual Studio Code. Create a .env file and save the following variables:
| Variable name | Variable value |
|---|---|
| CV_KEY | Azure Cognitive Services key |
| CV_ENDPOINT | Azure Cognitive Services endpoint |
| POSTGRES_HOST | PostgreSQL cluster coordinator name |
| POSTGRES_DB_NAME | PostgreSQL cluster database name |
| POSTGRES_USER | PostgreSQL cluster admin username |
| POSTGRES_PASSWORD | PostgreSQL cluster admin password |
Import the following libraries and 3 functions from the azurecv.py file.
| |
Insert a new code cell and add the following code, which will load the image file paths and the vector embeddings generated in a previous section.
| |
In a new code cell, create a Pandas Dataframe with two columns: one for the image file paths and one for the corresponding vector embeddings (converted to a string representation).
| |
Then, you will connect to the Azure Cosmos DB for PostgreSQL cluster. The following code forms a connection string using the environment variables for your Azure Cosmos DB for PostgreSQL cluster and creates a connection pool to your Postgres database. After that, a cursor object is created, which can be used to execute SQL queries with the execute() method.
| |
| |
| |
Let’s add some data to our table. Inserting data into a PostgreSQL table can be done in several ways. I chose not to use the pandas.DataFrame.to_sql() method for inserting data into our PostgreSQL table because it is relatively slow. Instead, I use the COPY FROM STDIN command to add the data.
The following code creates a temporary table with the same columns as the imagevectors table, and the data from the dataframe is copied into it. The data from the temporary table is then inserted into the imagevectors table, taking into account any potential conflicts that may arise due to duplicate keys (which could happen if the code is run multiple times).
| |
To view the first 10 rows inserted into the table, run the following code:
| |
After populating the table with vector data, you can use this image collection to search for images that are most similar to a reference image or a text prompt. The workflow is summarized as follows:
SELECT statements and the built-it vector operators of the PostgreSQL database.display_image_grid() function.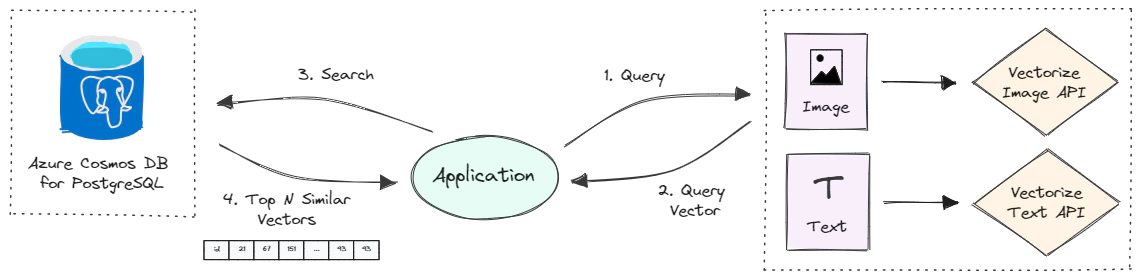
Let’s understand how a simple SELECT statement works. Consider the following query:
| |
This query computes the cosine distance (<=>) between the given vector ([0.003, …, 0.034]) and the vectors stored in the imagevectors table, sorts the results by the calculated distance, and returns the five most similar images (LIMIT 5).
The PostgreSQL pgvector extension provides 3 operators that can be used to calculate similarity:
| Operator | Description |
|---|---|
<-> | Euclidean distance |
<#> | Negative inner product |
<=> | Cosine distance |
An example of a text-to-image search process can be found below. For an example of an image-to-image search, please refer to the Jupyter Notebook in my GitHub repository.
| |
In this post, we explored the concepts of “embeddings”, “vector search”, and “vector database” and created a simple image vector similarity search system with the Azure Computer Vision Image Retrieval APIs and Azure Cosmos DB for PostgreSQL. If you’d like to dive deeper into this topic, here are some helpful resources.

Written By
I am a Back-End Engineer at NET2GRID in Greece, with an integrated Master's degree in Electrical and Computer Engineering from the Aristotle University of Thessaloniki. I am interested in AI, IoT, Wireless Communications, and Cloud Technologies, as well as in applications of technology in healthcare and education. I am also a Microsoft AI MVP.
Explore vector similarity search using the Hierarchical Navigable Small World (HNSW) index of pgvector on Azure Cosmos DB for PostgreSQL.

Explore vector similarity search using the Inverted File with Flat Compression (IVFFlat) index of pgvector on Azure Cosmos DB for PostgreSQL.

Learn how to write SQL queries to search for and identify images that are semantically similar to a reference image or text prompt using pgvector.
My presentation about vector search with Azure AI Vision and Azure Cosmos DB for PostgreSQL at the Azure Cosmos DB Usergroup.