
Use HNSW index on Azure Cosmos DB for PostgreSQL for similarity search
Explore vector similarity search using the Hierarchical Navigable Small World (HNSW) index of pgvector on Azure Cosmos DB for PostgreSQL.
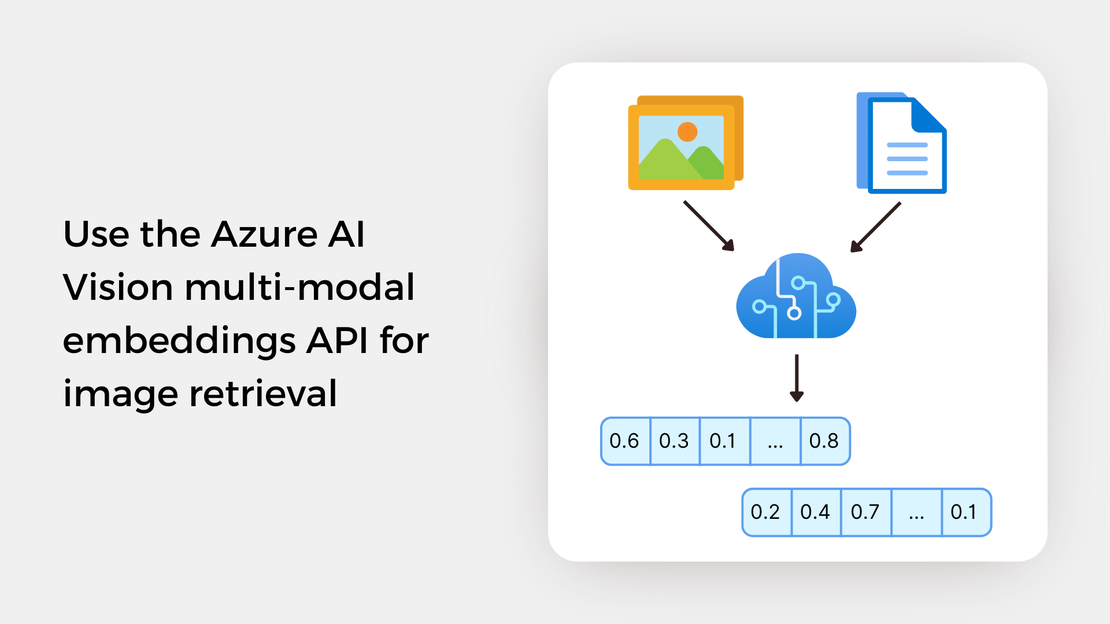
Welcome to a new learning series about image similarity search with pgvector, an open-source vector similarity search extension for PostgreSQL databases. I find vector search an intriguing technology, and I’ve decided to explore it! Throughout this series, I will discuss the basic concepts of vector search, introduce you to the multi-modal embeddings API of Azure AI Vision, and guide you in building an image similarity search application using Azure Cosmos DB for PostgreSQL.
Conventional search systems rely on exact matches on properties like keywords, tags, or other metadata, lexical similarity, or the frequency of word occurrences to retrieve similar items. Recently, vector similarity search has transformed the search process. It leverages machine learning to capture the meaning of data, allowing you to find similar items based on their content. The key idea behind vector search involves converting unstructured data, such as text, images, videos, and audio, into high-dimensional vectors (also known as embeddings) and applying nearest neighbor algorithms to find similar data.
In this tutorial, you learn how to:
To proceed with this tutorial, ensure that you have the following prerequisites installed and configured:
Comparing unstructured data is challenging, in contrast to numerical and structured data, which can be easily compared by performing mathematical operations. What if we could convert unstructured data, such as text and images, into a numerical representation? We could then calculate their similarity using standard mathematical methods.
These numerical representations are called vector embeddings. An embedding is a high-dimensional and dense vector that summarizes the information contained in the original data. Vector embeddings can be computed using machine learning algorithms that capture the meaning of the data, recognize patterns, and identify similarities between the data.
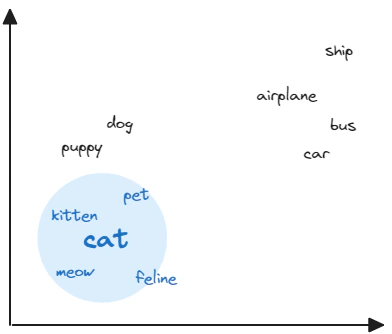
The numerical distance between two embeddings, or equivalently, their proximity in the vector space, represents their similarity. Vector similarity is commonly calculated using distance metrics such as Euclidean distance, inner product, or cosine distance.
Cosine is the similarity metric used by Azure AI Vision. This metric measures the angle between two vectors and is not affected by their magnitudes. Mathematically, cosine similarity is defined as the cosine of the angle between two vectors, which is equal to the dot product of the vectors divided by the product of their magnitudes.
Vector similarity can be used in various industry applications, including recommender systems, fraud detection, text classification, and image recognition. For example, systems can use vector similarities between products to identify similar products and create recommendations based on a user’s preferences.
A vector search system works by comparing the vector embedding of a user’s query with a set of pre-stored vector embeddings to find a list of vectors that are the most similar to the query vector. The diagram below illustrates this workflow.
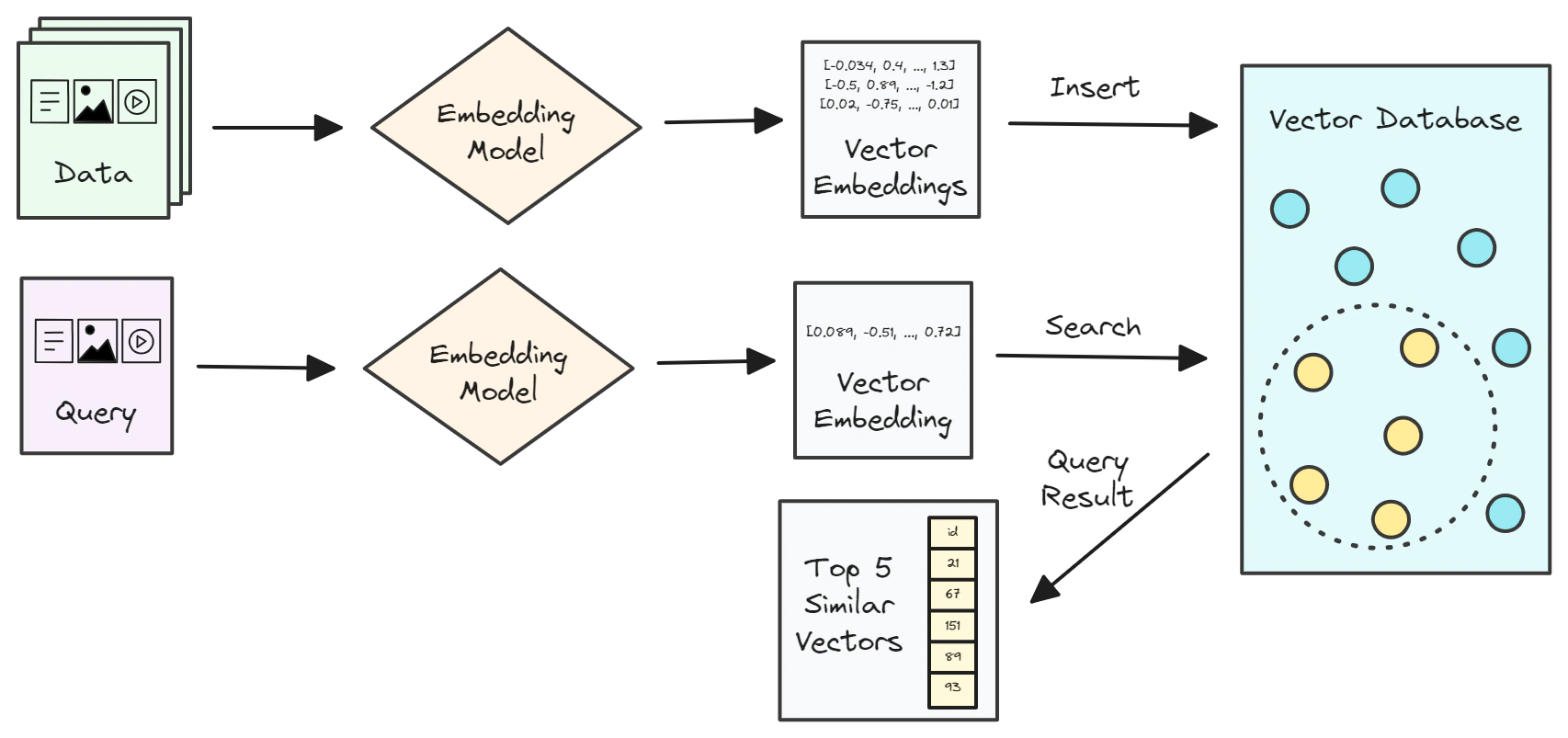
Vector embeddings are usually stored in a vector database, which is a specialized type of database that is optimized for storing and querying vectors with a large number of dimensions. You will learn more about vector databases in one of the following posts in this series.
Azure AI Vision provides two APIs for vectorizing image and text queries: the Vectorize Image API and the Vectorize Text API. This vectorization converts images and text into coordinates in a 1024-dimensional vector space, enabling users to search a collection of images using text and/or images without the need for metadata, such as image tags, labels, or captions.
Let’s learn how the multi-modal embeddings APIs work.
Open the Azure CLI.
Create a resource group using the following command:
| |
Create an Azure AI Vision in the resource group that you have created using the following command:
| |
Before using the multi-modal embeddings APIs, you need to store the key and the endpoint of your Azure AI Vision resource in an environment (.env) file.
Let’s review the following example. Given the filename of an image, the get_image_embedding function sends a POST API call to the retrieval:vectorizeImage API. The binary image data is included in the HTTP request body. The API call returns a JSON object containing the vector embedding of the image.
| |
Similarly to the example above, the get_text_embedding function sends a POST API call to the retrieval:vectorizeText API.
| |
The following code calculates the cosine similarity between the vector of the image and the vector of the text prompt.
| |
In this article, you’ve learned the basics of vector search and explored the multi-modal embeddings API of Azure AI Vision. In the next post, you will create vector embeddings for a collection of paintings’ images.
Here are some helpful learning resources:

Written By
I am a Back-End Engineer at NET2GRID in Greece, with an integrated Master's degree in Electrical and Computer Engineering from the Aristotle University of Thessaloniki. I am interested in AI, IoT, Wireless Communications, and Cloud Technologies, as well as in applications of technology in healthcare and education. I am also a Microsoft AI MVP.
Explore vector similarity search using the Hierarchical Navigable Small World (HNSW) index of pgvector on Azure Cosmos DB for PostgreSQL.

Explore vector similarity search using the Inverted File with Flat Compression (IVFFlat) index of pgvector on Azure Cosmos DB for PostgreSQL.

Learn how to write SQL queries to search for and identify images that are semantically similar to a reference image or text prompt using pgvector.
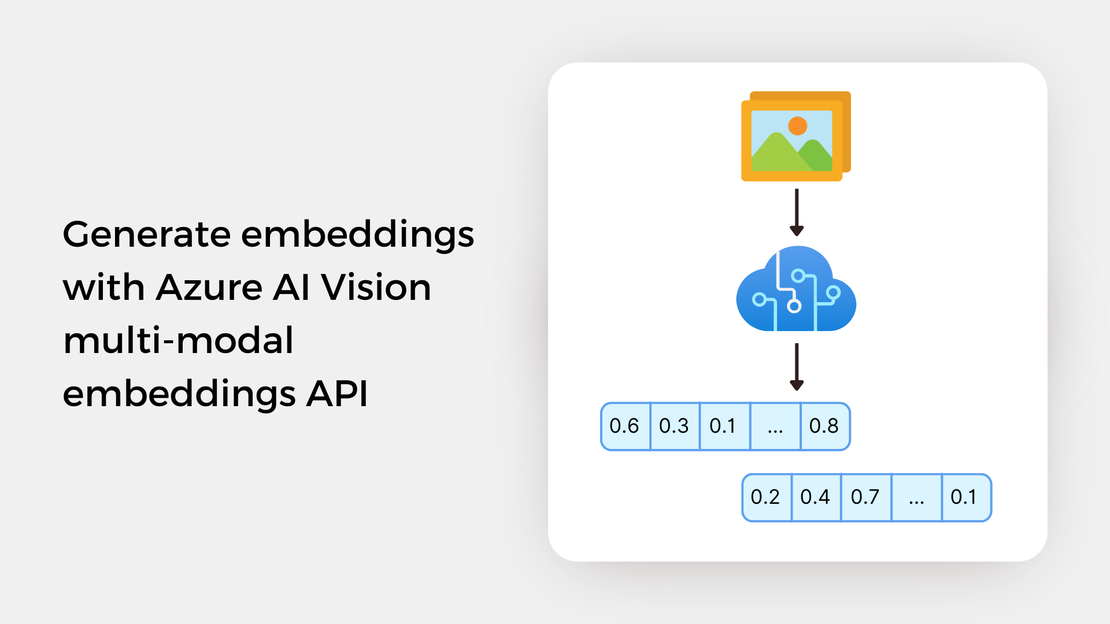
Discover the art of generating vector embeddings for paintings’ images using the Azure AI Vision multi-modal embeddings APIs in Python.